Molte aziende sono restie ad esternalizzare i propri servizi IT nel cloud. Un primo motivo è il timore di esporre dati sensibili, o comunque privati, in un ambiente ritenuto poco sicuro; inoltre, si preferisce posticipare l’argomento per il principio di salvaguardare gli investimenti in hardware fatti negli anni precedenti.
Per quanto riguarda la prima preoccupazione, è importante osservare che la sicurezza è una “responsabilità condivisa” tra il cliente e il cloud provider. Al provider spetta il compito di mantenere la sicurezza “del” cloud, proteggendo cioè le infrastrutture fisiche (hardware, network, ecc.) su cui girano i servizi, mentre l’utente è responsabile della sicurezza “nel” cloud ossia dei servizi che sceglie di utilizzare e delle loro varie configurazioni.
Accettare questa responsabilità è il primo passo per affrontare il timore iniziale perché questa nuova consapevolezza spinge i manager dell’azienda a voler sbrogliare meticolosamente tutti gli aspetti del problema coinvolgendo i colleghi dell’IT interno o il partner esterno a cui il Cliente si appoggia.
Invece per quanto riguarda la necessità di salvaguardare gli investimenti fatti in passato la soluzione c’è ed è quella di aggiungere un insieme di servizi sul cloud per estendere l’infrastruttura hardware esistente e di godere dei vantaggi di entrambi gli ambienti. Questa soluzione viene chiamata cloud ibrido o hybrid cloud.
Un comodo primo approccio al cloud ibrido è quello di estendere l’infrastruttura di storage esistente.
La migrazione dello storage è il primo caso pratico che può essere preso in esame sia per la sua semplicità tecnica che per la facilità con cui si calcolano i costi (e di conseguenza i vantaggi economici) rispetto all’attuale soluzione on-premise.
L’obiettivo di questo articolo è dunque quello di descrivere l’approccio all’hybrid cloud storage, comparando inizialmente i principali modelli di archiviazione on-premise e l’ampio portafoglio di servizi di storage AWS per aiutare i Clienti ad associare i modelli esistenti con i servizi AWS. Infine verrà descritto AWS Storage Gateway, il servizio che permette di estendere l’archiviazione in locale con quella su cloud AWS.
L’archiviazione hybrid cloud: cos’è
Come già introdotto, l’hybrid cloud storage, o archiviazione hybrid cloud, è un’architettura che collega i sistemi di storage on-premise con quelli del cloud, trattando l’intera architettura come un unico sistema di archiviazione.
L’archiviazione ibrida sul cloud viene implementata con applicazioni software proprietarie oppure installando localmente un dispositivo che funge da gateway e gestisce ciò che viene archiviato localmente e ciò che transita nel cloud.
Un primo utilizzo di questa architettura è quello di estendere lo spazio di archiviazione locale con quello sul cloud. In questo caso, il gateway può ottimizzare intelligentemente questo processo mantenendo i dati utilizzati di frequente in loco e spostando quelli meno utilizzati nel cloud. Un secondo modo di utilizzare l’hybrid cloud storage è quello di eseguire i backup dei dati direttamente sul cloud piuttosto che replicare i backup in un data center secondario.
I modelli di storage on-premise
Prima però di passare ad analizzare lo storage hybrid cloud, vediamo quali sono i modelli di archiviazione comunemente utilizzati on-premise.
SAN
Una SAN (Storage Area Network) è una rete (o sottorete), ad alta velocità di trasmissione, che ospita svariati dispositivi di memorizzazione di massa. I protocolli attualmente più diffusi per la comunicazione all’interno di una SAN, sono FCP (Fibre Channel Protocol) ed iSCSI (Internet SCSI). Lo scopo di una SAN è quello di rendere le risorse di storage disponibili a qualsiasi computer connesso sulla rete garantendo alte prestazioni e un accesso diretto ai dischi. La SAN è spesso utilizzata da database distribuiti per il data warehousing, per applicazioni enterprise o per il backup dei dati e il disaster recovery.
NAS
Un NAS (Network Attached Storage) è una risorsa di archiviazione disponibile sulla rete locale dotata di un sistema operativo, di diversi dischi e di un file system dove i dati vengono archiviati in cartelle all’interno di una directory gerarchica di file.
Questi file system utilizzano protocolli di comunicazione come NFS (Network File Storage) per carichi di lavoro Linux, SMB (Server Message Block ) o CIFS (Common Internet File System) per carichi di lavoro e condivisione di file su Windows.
L’archiviazione NAS viene spesso utilizzata come repository di file all’interno di cartelle condivise per utenti e applicazioni.
Disk e tape drive
Sebbene meno diffusi rispetto ai primi due, l’archiviazione su disco o su nastro è ancora utilizzata da diverse realtà per la gestione delle strategie di Disaster Recovery (DR), dei backup e della loro storicizzazione.
Perché scegliere lo storage sul cloud AWS?
Da oltre 15 anni, milioni di Clienti nel mondo, utilizzano i servizi di archiviazione di AWS. Il successo di questa ampia adozione si spiega facilmente se riconosciamo che i servizi offerti da AWS hanno soddisfatto le priorità strategiche della maggior parte di chi ne ha fatto uso, in particolare:
- riduzione dei costi per l’archiviazione
- aumento della agilità aziendale per l’approvvigionamento di nuovo spazio di archiviazione
- spinta della capacità di innovare
- rafforzamento della sicurezza dei dati
L’aderenza alla prima priorità, la riduzione dei costi, si può dimostrare scomponendo il TCO (Total Cost of Ownership) ed analizzando 3 principali fattori di costo:
- l’utilizzo di servizi gestiti elimina la necessità di acquisto e di manutenzione dell’infrastruttura fisica per l’archiviazione
- i costi sono inferiori, perché calcolati in base allo spazio che effettivamente viene consumato, rispetto al un modello on-premise in cui si dispone di un’ infrastruttura sovradimensionata atta a coprire l’esigenza di crescita nel tempo delle informazioni da archiviare
- in base alla frequenza ed alla rapidità con cui si deve aver accesso ai dati archiviati, è possibile ottimizzare ulteriormente i costi
L’agilità è una componente intrinseca del cloud in quanto ogni risorsa (non solo quelle legate allo storage) viene resa disponibile velocemente per soddisfare le esigenze aziendali, evitando complesse pianificazioni.
Una volta che i dati sono archiviati nel cloud AWS, essi possono alimentare ulteriori servizi, come l’analisi di Big Data, il Machine Learning o l’implementazione di applicazioni di elaborazione multimediale, nell’ottica di incrementare la spinta verso l’innovazione.
Infine AWS garantisce elevati standard di sicurezza oltre ad aver acquisito numerose certificazioni di conformità in grado di soddisfare i requisiti di quasi tutte le agenzie di regolamentazione in tutto il mondo.
I servizi di AWS storage
L’ampia offerta di servizi AWS per lo storage soddisfa tutti i modelli di archiviazione in locale che abbiamo visto precedentemente ed in alcuni casi, addirittura, ne estende le funzionalità.
Amazon Elastic Block Store (Amazon EBS)
Amazon EBS è un servizio di archiviazione a blocchi ad alte prestazioni progettato per essere collegato con istanze Amazon Elastic Compute Cloud (EC2).
Una volta collegato, apparirà come un disco rigido o un altro dispositivo a blocchi. L’istanza EC2 può quindi utilizzare il volume esattamente come fosse con un’unità locale, formattandolo con un file system o installando direttamente delle applicazioni.
I volumi EBS offrono capacità di archiviazione da 4GB a 16TB (64TB con volumi di tipo io2 Block Express) ed sono suddivisi in due macro-categorie: SSD per carichi di lavoro transazionali, in cui le prestazioni dipendono soprattutto dalla quantità di operazioni di I/O per secondo, e HDD per carichi di lavoro che richiedono un elevato tasso di throughput, in cui le prestazioni dipendono cioè dalla quantità di MB trasferiti per secondo.
I volumi Amazon EBS vengono eseguiti in una specifica Availability Zone (AZ), vengono automaticamente replicati per proteggere dagli errori dei singoli componenti e sono progettati per una durabilità del 99,999%. Nel caso si fossero migrate le applicazioni aziendali nel cloud, Amazon EBS permette di costruire la propria SAN dedicata.
Amazon EFS (Elastic File System) e Amazon FSx per Windows File Server
Amazon EFS fornisce un file system elastico semplice, scalabile e completamente gestito.
Con Amazon EFS, è possibile creare un file system, montarlo su un’istanza Amazon EC2, quindi leggere e scrivere dati da e verso il file system.
Amazon EFS utilizza il protocollo Network File System v4.0/4.1 (NFS v4) e per questo viene utilizzato con AMI (Amazon Machine Images) di tipo Linux.
Amazon FSx per Windows File Server fornisce invece uno storage di file completamente gestito, altamente affidabile e scalabile, accessibile tramite il protocollo SMB (Server Message Block). È basato su Windows Server e offre un’ampia gamma di funzionalità amministrative come le quote utenti, le liste di controllo degli accessi (ACL) e l’integrazione con Microsoft Active Directory (AD). Offre opzioni di distribuzione single-AZ e multi-AZ, backup gestiti e crittografia dei dati. Lo storage di file Amazon FSx è accessibile da istanze di calcolo e dispositivi Windows ma poiché è possibile accedere alle condivisioni di file SMB anche da Linux e MacOS, qualsiasi applicazione o utente può accedere allo storage a prescindere dal sistema operativo.
Amazon EFS e FSx per Windows File Server servono, nel cloud, carichi di lavoro di applicazioni e di utenti tradizionalmente serviti dalle NAS on-premise.
Amazon Simple Storage Service (Amazon S3)
Amazon S3 è un servizio di storage di oggetti. In esso i dati vengono archiviati e gestiti come unità indipendenti, dette oggetti, che contengono ciascuno una chiave, dei dati ed eventualmente dei metadati. Gli oggetti possono essere rappresentati come unità modulari ed i metadati ne descrivono le proprietà quali autorizzazioni, privacy, protezioni, versione ed altre informazioni.
S3 è utilizzato per archiviare e proteggere qualsiasi quantità di dati e per una vasta gamma di casi d’uso: data lake, archiviazione, backup e ripristino, siti web statici, salvataggio di dati dai dispositivi IoT e analisi di big data.
S3 è suddiviso in 6 diverse classi di archiviazione che, con costi differenti, soddisfano diverse esigenze in termini di durabilità, affidabilità, frequenza di accesso e tempi di recupero del dato.
Queste classi includono
- S3 Standard per l’archiviazione di dati di uso operativo
- S3 Standard-Infrequent Access (IA S3) e S3 One Zone-Infrequent Access (One Zone – IA S3) per i dati che richiedono un accesso meno frequente
- Amazon S3 Glacier (S3 Glacier) e Amazon S3 Glacier Deep Archive (S3 Glacier Deep Archive) per l’archiviazione e la conservazione dei dati digitali a lungo termine
- per ultimo, S3 Intelligent-Tiering, che consente di transitare i dati intelligentemente tra le varie classi di archiviazione analizzando preventivamente il loro utilizzo
I dati sono acceduti attraverso chiamate API (Application Programming Interface) e per questo non trovano un immediato riscontro nei servizi on-premise descritti precedentemente. Tuttavia S3 è il servizio ideale per salvare qualsiasi formato di dati e si presta a creare soluzioni di backup e ripristino dei dati, di Disaster Recovery e di archiviazione a lungo termine.
L’accesso all’hybrid cloud con AWS Storage Gateway
Una volta studiati i principali servizi di storage on-premise e cloud, possiamo mappare ciascun dispositivo hardware per l’archiviazione locale con il suo corrispettivo servizio in AWS ottenendo la seguente rappresentazione grafica:
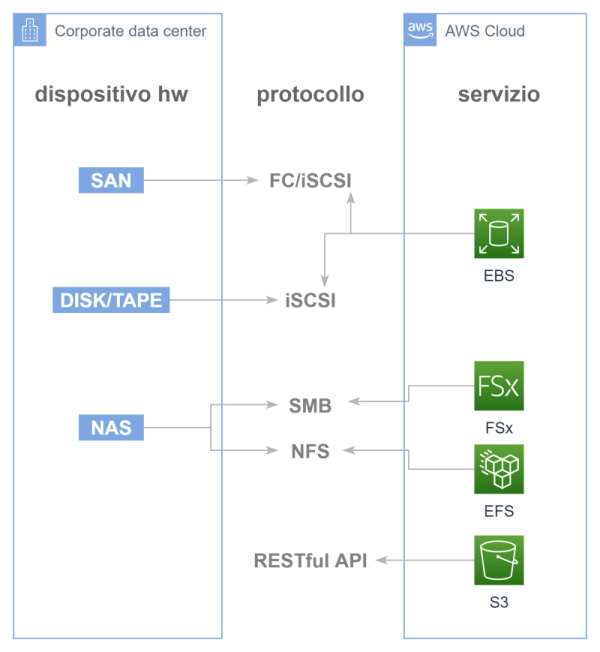
Possiamo osservare che il servizio S3 difficilmente trova una corrispondenza all’interno dell’organizzazione aziendale, considerando la modalità di accesso via API, mentre vedremo che, nel caso di archiviazione ibrida, esso svolge un ruolo protagonista.
Il servizio AWS che permette di unire ed estendere i 2 ambienti si chiama AWS Storage Gateway: grazie allo storage ibrido sul cloud è quindi possibile accedere ai dati on-premise contemporaneamente alle funzionalità avanzate dei servizi Amazon S3, Amazon S3 Glacier, Amazon S3 Glacier Deep Archive, Amazon FSx for Windows File Server e Amazon EBS.
Con AWS Storage Gateway, file, database e applicazioni di backup possono continuare a funzionare senza alcun cambiamento mentre i dati sono salvati in sicurezza in AWS e accessibili da altri servizi AWS.
AWS Storage Gateway è in funzione sul cloud AWS mentre localmente è necessario installare uno o più gateway specifici: AWS Storage Gateway può essere collegato ad un File, Tape o Volume Gateway disponibili on-premise. Questi gateway possono essere implementati con diversi metodi in base alle esigenze dell’infrastruttura locale: come macchina virtuale, eseguita localmente su VMware ESXi, Microsoft Hyper-V o Linux KVM, acquistati come dispositivi hardware dedicati oppure come VM in VMware Cloud on AWS o come AMI in Amazon EC2.
Generalizzando ed indipendentemente dal tipo di gateway utilizzato, i dati vengono transitati nel cloud ottimizzando il trasferimento: i dati utilizzati più frequentemente vengono mantenuti in una cache locale sul gateway mentre gli altri vengono trasferiti in modo asincrono sul cloud storage.
Vediamo in dettaglio ciascuna configurazione.
File Gateway
Sono disponibili 2 sotto-tipi di gateway per l’archiviazione di file: S3 File Gateway e FSx File Gateway.
S3 File Gateway, permette di archiviare dati di file come oggetti su Amazon S3 per backup oppure per implementare data lake e processi di ML. Nel caso si volessero archiviare dati per lungo tempo, è possibile definire delle regole tali per cui i dati vengono fatti transitare da S3 a S3 Glacier, ottimizzando così i costi di archiviazione.
I dati vengono archiviati e recuperati in Amazon S3 utilizzando i protocolli standard NFS (Network File System) o SMB (Server Message Block). Opzionalmente può essere collegato ad un AD aziendale per l’accesso autenticato degli utenti alla condivisione SMB dei file.

FSx File Gateway viene invece utilizzato per la condivisioni di file tra utenti o gruppi di lavoro.
Offre accesso locale veloce e a bassa latenza a condivisioni di file completamente gestite, altamente affidabili e scalabili nel cloud utilizzando il protocollo SMB. È completamente integrato nel dominio aziendale e gli utenti possono archiviare e accedere a cartelle e file in Amazon FSx come farebbero utilizzando un Windows File Server, inclusi il supporto di NTFS, le shadow copies e le liste di controllo degli accessi (ACL).

Volume Gateway
Volume Gateway espone alle applicazioni on-premise, volumi a blocchi iSCSI nel cloud. Inoltre, archivia e gestisce trasparentemente i dati locali in Amazon S3 e può essere configurato sia in modalità “cache” che in modalità “storage”.
Nella modalità “cached Volume Gateway”, i dati principali sono archiviati su Amazon S3, mantenendo in una cache locale i dati a cui si accede più frequentemente per accedervi con bassa latenza. Nella modalità “stored Volume Gateway”, i dati principali sono archiviati localmente ed è possibile accedere all’intero set di dati con bassa latenza, mentre viene eseguito un backup asincrono su Amazon S3.
Con entrambe le modalità, una volta che i dati sono su S3, utilizzando AWS Backup è possibile eseguire copie dei volumi da archiviare come snapshot di Amazon EBS. L’utilizzo degli snapshot consente di creare copie con versioni ottimizzate in termini di spazio dei volumi per garantire un ulteriore livello di protezione dei dati, il loro ripristino, la migrazione e altre possibilità di utilizzo sul cloud.

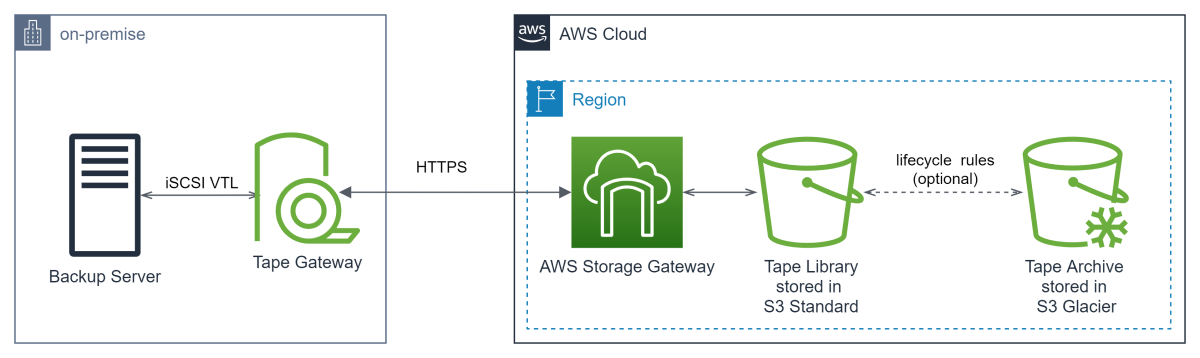
Tape Gateway
Tape Gateway consente di sostituire l’uso di nastri fisici in locale con nastri virtuali in AWS senza cambiare i flussi di lavoro esistenti di backup. Inoltre, offre supporto per tutte le principali applicazioni di backup (clicca qui per l’elenco completo) e memorizza nella cache locale i nastri virtuali per accedere ai dati con bassa latenza. Tape Gateway crittografa i dati tra il gateway e AWS per garantire il trasferimento sicuro e comprime i dati per ridurre al minimo i costi dello storage S3. Infine è possibile creare un archivio storico, a basso costo, su Amazon S3 Glacier o Amazon S3 Glacier Deep Archive utilizzando le lifecycle rules.
Conclusioni: hybrid cloud e poi?
Ad oggi molti clienti hanno iniziato ad utilizzare AWS Storage Gateway per implementare una strategia hybrid cloud di storage dei dati. Grazie a questo primo passo, hanno potuto testare l’affidabilità dei servizi AWS e constatare l’effettivo risparmio rispetto alle precedenti soluzioni on-premise.
Molti, dopo questa prima esperienza positiva hanno intrapreso il percorso di migrazione nel cloud per molte altre parti (se non tutte) dell’infrastruttura locale. Perché l’hanno fatto? Perché il cambiamento è difficile in sé ed affrontarlo avendo già un’esperienza positiva alle spalle, semplifica tutto.
Spero che questo articolo possa aiutare ed incentivare chi ancora non ha mosso i primi passi nell’adozione del cloud oppure non abbia ancora pensato di estendere o migrare i servizi di storage.
Se posso permettermi un consiglio: partite avendo chiaro un obiettivo semplice e quantificabile. Raggiunto questo, avrete maturato l’esperienza per andare oltre e ambire ad obiettivi più ambiziosi.
Per qualsiasi richiesta o domande, potete contattarmi su LinkedIn o utilizzare il modulo Contatti.